本文共 953 字,大约阅读时间需要 3 分钟。
一 OAuth2解决什么问题
1 开放系统间授权
照片拥有者想要在云冲印服务上打印照片,云冲印服务需要访问云存储服务上的资源。
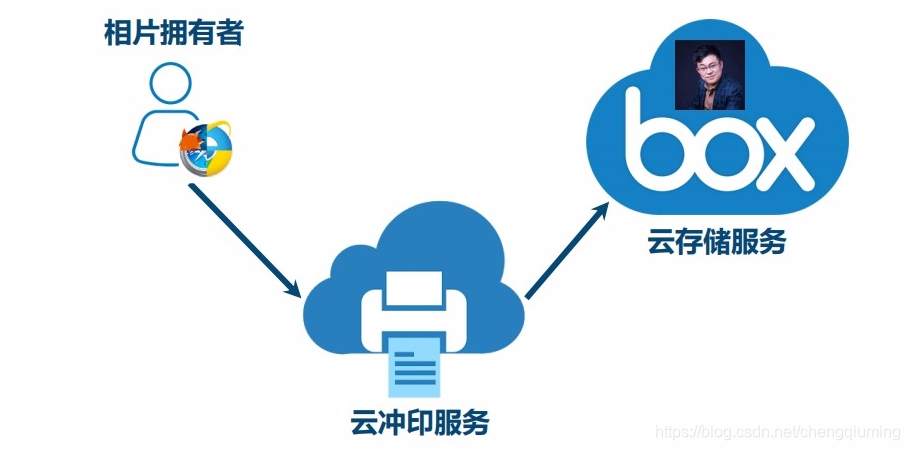
2 图例
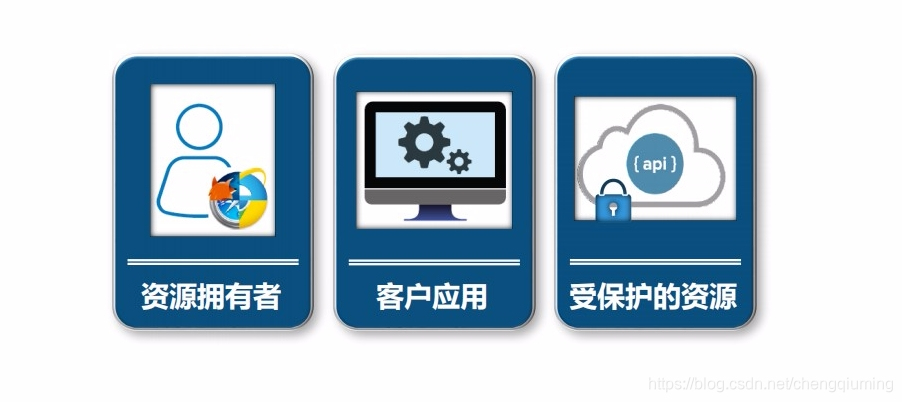
资源拥有者:照片拥有者
客户应用:云冲印
受保护的资源:照片
3 方式一:用户名密码复制
用户将自己的"云存储"服务的用户名和密码,告诉"云冲印",(即资源服务器的用户名和密码存储在客户应用服务器上)后者就可以读取用户的照片了。这样的做法有以下几个严重的缺点。
a "云冲印"为了后续的服务,会保存用户的密码,这样很不安全。
b Google不得不部署密码登录,而我们知道,单纯的密码登录并不安全。
c "云冲印"拥有了获取用户储存在Google所有资料的权力,用户没法限制"云冲印"获得授权的范围和有效期。
d 用户只有修改密码,才能收回赋予"云冲印"的权力。但是这样做,会使得其他所有获得用户授权的第三方应用程序全部失效。
e 只要有一个第三方应用程序被破解,就会导致用户密码泄漏,以及所有被密码保护的数据泄漏。
总结:
将受保护的资源中的用户名和密码存储在客户应用的服务器上,使用时直接使用这个用户名和密码登录
适用于同一公司内部的多个系统,不适用于不受信的第三方应用
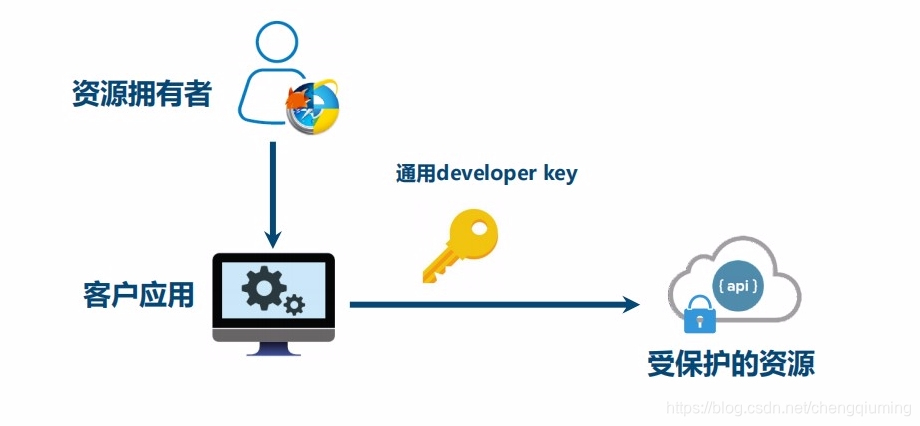
4 方式二:通用开发者key
key是事先在"云存储"服务和"云冲印"服务间约定好的,适用于合作商或者授信的不同业务部门之间
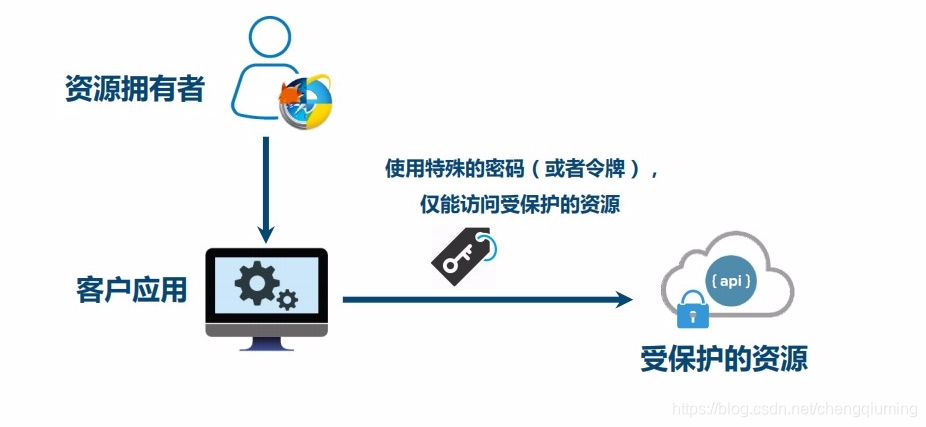
5 方式三:颁发令牌
需要考虑如何管理令牌、颁发令牌、吊销令牌,需要统一的申请令牌和颁发令牌的协议。

二 OAuth2简介
1 OAuth主要角色
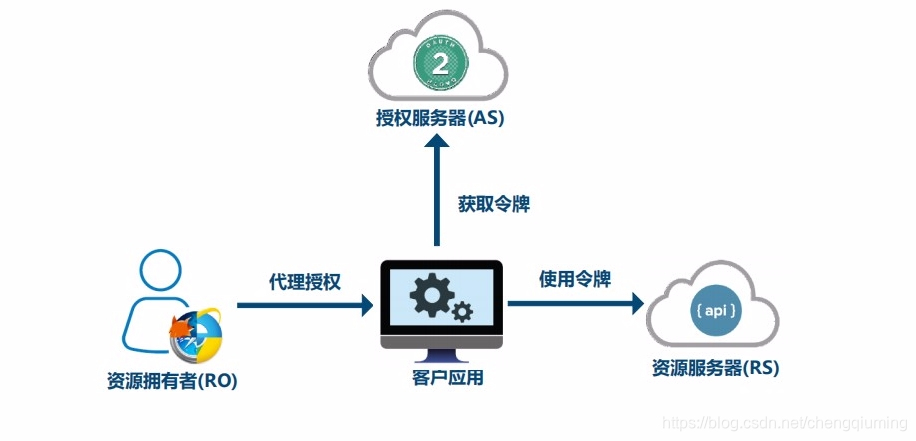
2 最简向导
川崎高彦:OAuth2领域专家,开发了一个OAuth2 sass服务,OAuth2 as Service,并且做成了一个公司
在融资的过程中为了向投资人解释OAuth2是什么,于是写了一篇文章,《OAuth2最简向导》
三 OAuth2的应用
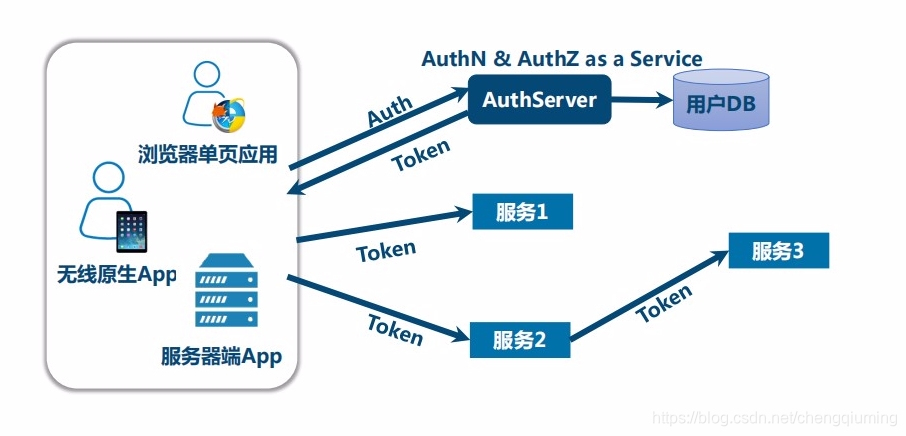
1 微服务安全
现代微服务中系统微服务化以及应用的形态和设备类型增多,不能用传统的登录方式
核心的技术不是用户名和密码,而是token,由AuthServer颁发token,用户使用token进行登录
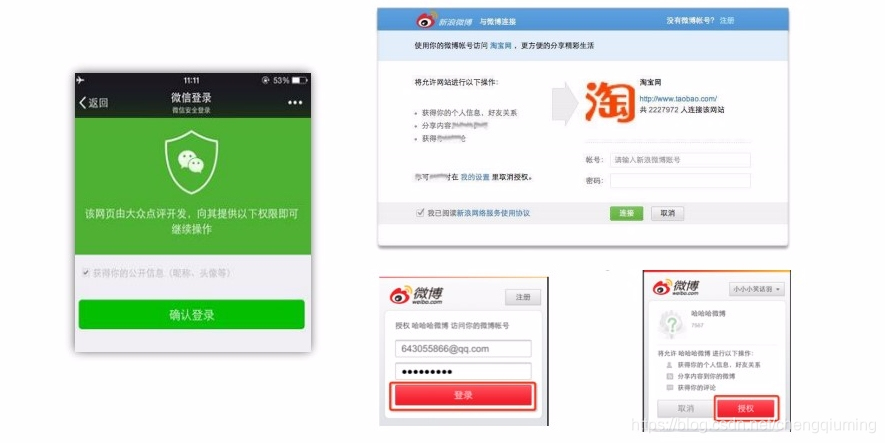
2 社交登录
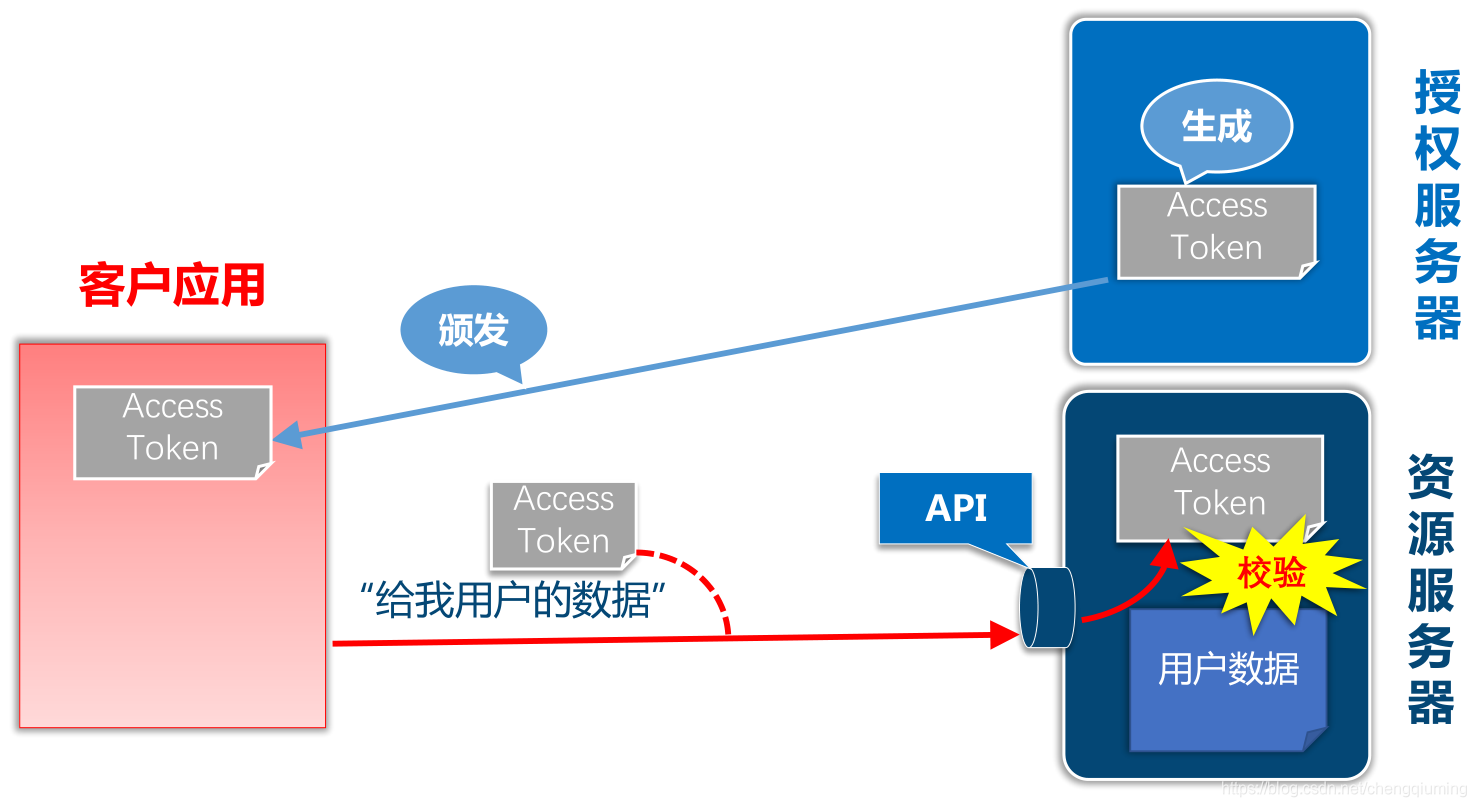
四 OAuth2.0最简向导核心图解
1 RFC 6749, OAuth 2.0授权框架
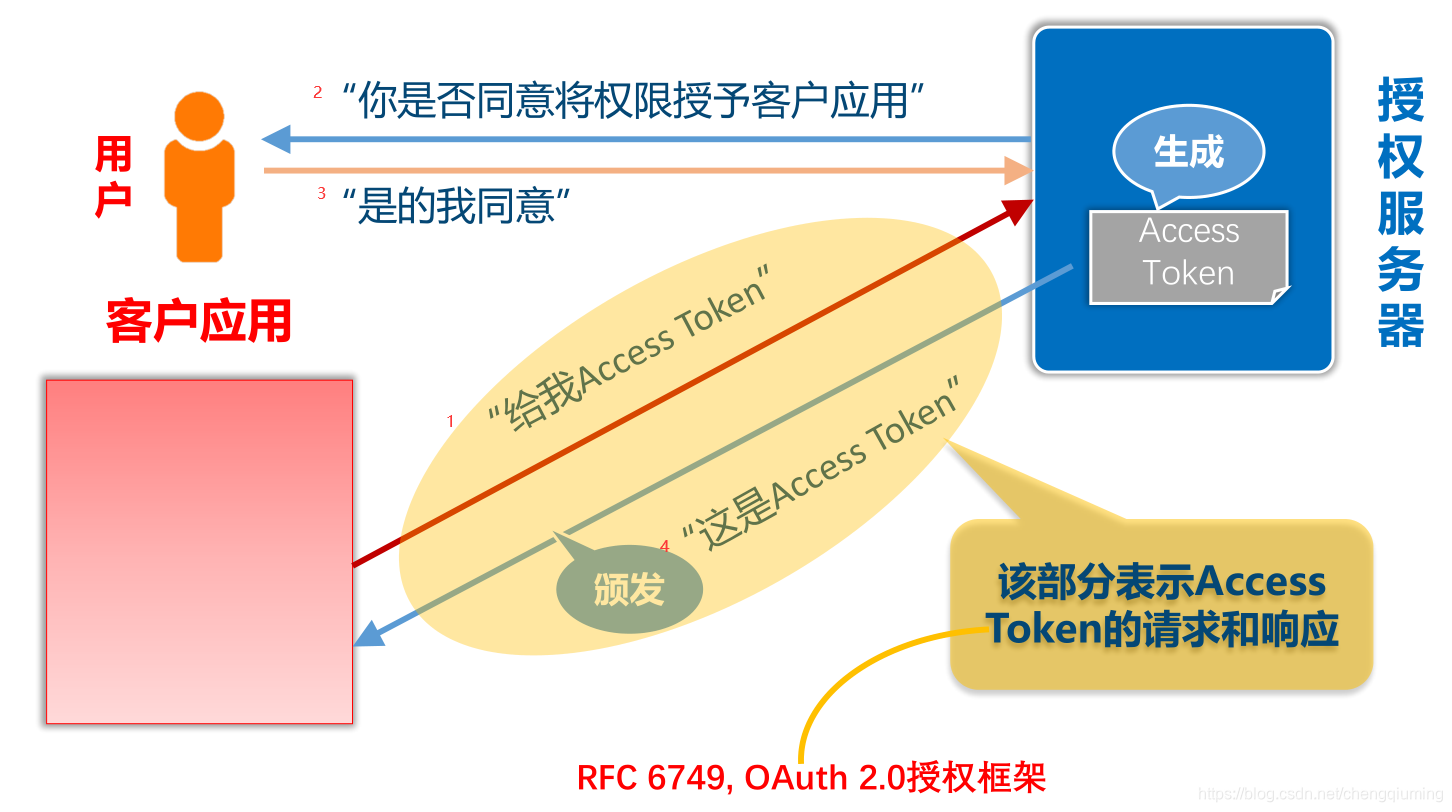
2 校验Access Token具有访问用户数据的权限
转载地址:http://reqj.baihongyu.com/